Reading large spreadsheets with CFML
If you've ever had to work with large spreadsheets in CFML you may have run up against out-of-memory (OOM) errors. This is because by default the entire workbook data has to be loaded into the available JVM memory before you can do anything with it. That means that the size of the workbook and the amount of heap space available are critical factors.
I've written before on how you can overcome this with the Spreadsheet CFML library using the streaming workbook (SXSSF) format, but that only applies when writing spreadsheets. Reading large files has still been a challenge.
POI, the java library from Apache which powers the Spreadsheet CFML library, does have an API for streaming incoming spreadsheet files but working with it requires a knowledge of SAX and java far beyond my skill-set.
However I've discovered a complementary java library, written by a POI contributor, which provides a straightforward interface to that API, albeit with some limitations.
readLargeFile()
The latest release (v3.5.0) of the Spreadsheet CFML library integrates the excel-streaming-reader library functionality to provide a new readLargeFile() method.
Before we dive into an example of what it can do, let's consider the limitations I mentioned so we're aware of what it can't.
Limitations
1. XLSX only
As with SXSSF for writing, the file must be an XML format or "xlsx" type. Binary spreadsheets ending ".xls" cannot be read this way.
2. Returns data, not a workbook
By default readLargeFile() returns a CFML query object. Unlike read() there's no option to return a workbook object simply because the java object returned by the streaming reader doesn't support the majority of methods found in a regular XSSF object. You wouldn't therefore be able to pass it to many other library methods and expect things to work.
But if you just need to get data out of a big file this shouldn't be an issue.
It can however return CSV or HTML derived from the query.
3. Not all read() options are available
Most but not all of the regular read() method options are available. In particular, you cannot specify rows or columns. Again this is down to the limited nature of the streamed workbook object which does not have random access to the data.
4. Doesn't (yet) work in Adobe ColdFusion
This pains me as I've put in quite a lot of effort to achieve feature parity between the CFML engines over the years, but for now I can't seem to get the streamed reader's open() method to work in ColdFusion. I'd love to hear from anyone with any insight into why.
Update Feburary 2025: As of version 4.4.0 of the library, readLargeFile() will work with supported versions of ColdFusion.
Demo: Reading a large file
To put it through its paces I'm going to set up a challenge: read a 100K row spreadsheet using a Lucee instance with just 128MB of heap.
I'll use Commandbox to spin up a Lucee 5.3 server with the following in its server.json
"jvm":{
"heapSize":128,
"minHeapSize":128
}Next, I'll create that humungous spreadsheet using SXSSF.
// dummy data generator
query function createData( numberOfColumns=5, numberOfRows=100000 ){
var columns = [];
var columnTypes = [];
var row = [];
var data = [];
//create the columns
for( var i=1; i <= arguments.numberOfColumns; i++ ){
columns.Append( "col#i#" );
row.Append( "Column #i#" );
columnTypes.Append( "VarChar" );
}
//add the required number of rows
for( var i=1; i<= arguments.numberOfRows; i++ ){
data.Append( row );
}
return QueryNew( columns.ToList(), columnTypes.ToList(), data );
}
// generate the large file using SXSSF
filepath = ExpandPath( "large.xlsx" );
spreadsheet = New spreadsheet.Spreadsheet();
spreadsheet.writeFileFromQuery( data=createData(), filepath=filepath, overwrite=true, streamingXml=true );As a control, let's see what usually happens when we try to read such a beast.
filepath = ExpandPath( "large.xlsx" );
spreadsheet = New spreadsheet.Spreadsheet();
extractedData = spreadsheet.read( src=filepath, format="query", headerRow=1 );
No surprises here: java.lang.OutOfMemoryError.
So now let's try the new readLargeFile() method wrapped in a timer.
filepath = ExpandPath( "large.xlsx" );
spreadsheet = New spreadsheet.Spreadsheet();
startTime = GetTickCount();
extractedData = spreadsheet.readLargeFile( src=filepath, headerRow=1 );
endTime = GetTickCount();
result.readTime = ( endTime - startTime ) & "ms";
result.recordsExtracted = extractedData.recordcount;
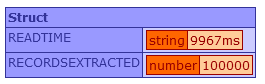
WriteDump( result );Which successfully completes this time in a shade under 10 seconds.
Tuning
Finally, although I haven't experimented with them much, there are a couple of tuning dials you can tweak which can be passed in within a struct called streamingReaderOptions.
bufferSize: the amount of memory in bytes to use as a buffer, defaulting to 1024.rowCacheSize: the number of rows to process at a time, defaulting to 10.
For example:
tuningOptions = { bufferSize: 4096, rowCacheSize: 50 };
extractedData = spreadsheet.readLargeFile( src=filepath, headerRow=1, streamingReaderOptions=tuningOptions );The Spreadsheet CFML library is available on Github.